
Extend CycleGAN for Real World Challenges – Joint Image Super-resolution & Deblurring, and Cross-domain Image Deblurring
Abstract
Inspired by previous work, in this paper, we present an unsupervised single-image deblurring method that’s capable of both joint image deblurring super-resolution and cross-domain image deblurring. To separate the blurring factor from content information, we consider image blur as a "style" and disentangle the blurring feature and content feature using separate encoders. We also use de-convolution techniques to encode content information at different scales.
Model
Our proposed method is a modification on top of the domain-specific image deblurring model in[2], just like [2] gets its inspiration from [1]. For completeness, we will still describe the overall framework of our model. Our model consists of two content encoders \(E_B^c\) and \(E_S^c\) for encoding content information in blurred and sharp image domains, respectively. A blurring feature encoder \(E^b\) is used to encode blurring feature information in the blurred image domain. Two generators \(G_B\) and \(G_S\) are used to generate blurred images and deblurred, sharp images; two domain discriminators \(D_B\) and \(D_S\) are used to discriminate synthetic blurred/sharp images from real blurred/sharp images. During training, the model takes a pair of training examples b∈B from the blurred image domain and s∈S from the sharp image domain, extract content information with the content encoders \(E_B^c\) and \(E_S^c\), and the blurring feature information with the feature encoder \(E^b\). Generator \(G_B\) takes the sampled blurring feature from \(E^b\) as well as the sharp image’s content encoding from \(E_S^c\) to "transfer" blurring effect and generate synthetic blurred image \(b_s\). Similarly, Generator \(G_S\) learns to construct sharp images from the sample blurring feature as well as the blurred image’s content embedding.The discriminators \(D_B\) and \(D_S\) are trained to distinguish real and synthetic images in their specific domains. Inspired by [3], the synthetic images in both domains are mapped back to their original blurred/sharp domain to encourage the content encoders \(E_S^c\), \(E_B^c\) to retain content information from the original sharp/blurred images.
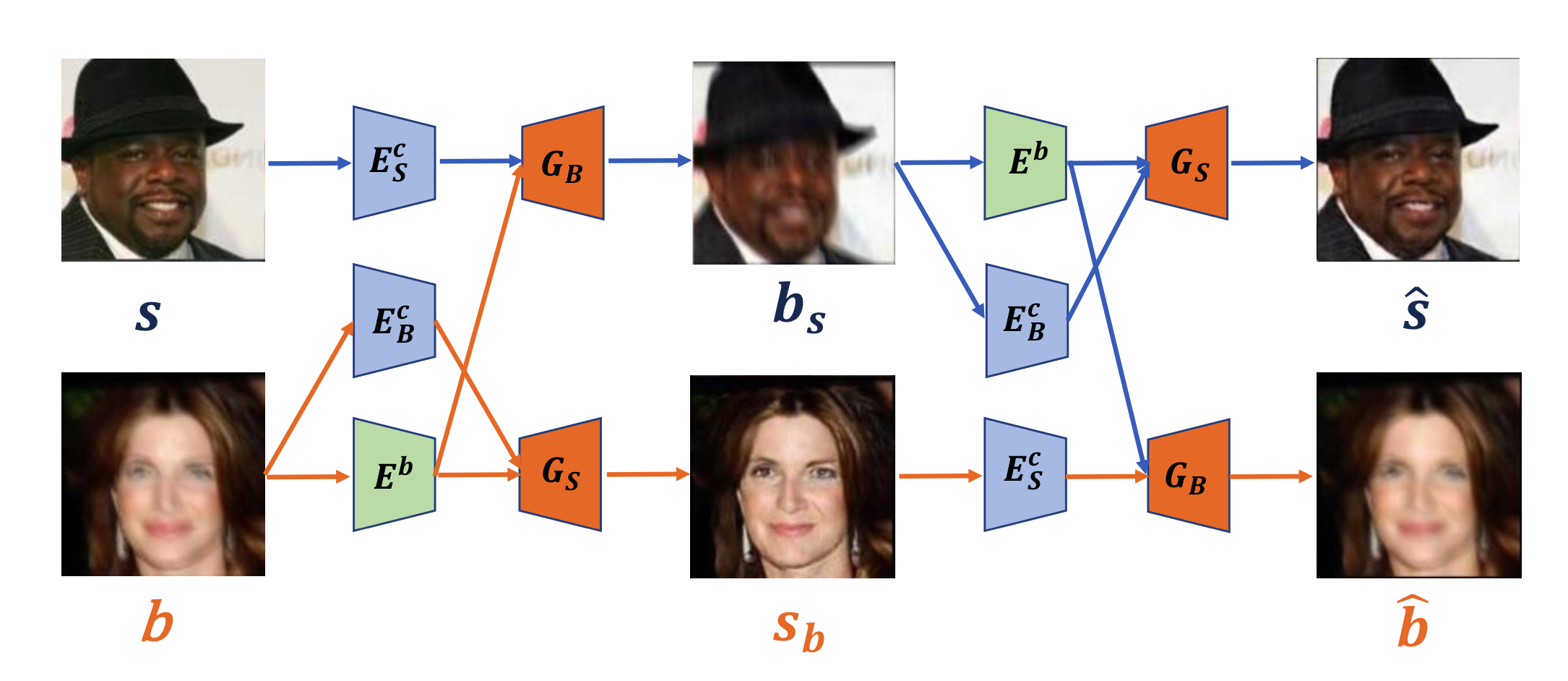
Disentangle content information from blurring feature information
By separating out content encoder and blurring feature encoder, our model framework encourages their disentanglement. Furthermore, we hypothesize that the distribution of blurring feature should be relatively simple. Therefore, we use a standard normal distribution p(z)∼N(0,1) to regularize it. Specifically, we minimize the KL-divergence between standard normal and the blurring feature distribution:
which is equivalent to minimizing
where μ and σ are the mean and standard deviation of the blurring feature distribution.
Jointly super-resolve and deblur images
We hypothesize that the unknown blur kernel should be scale-invariant, while content signal will be compressed in an image with lower resolution and smaller scale. In light of this, when jointly super-resolving and deblurring a low-resolution, blurred image, we keep our blur feature encoder intact. We use deconvolutional layers to learn to upsample low-resolution images for downstream processing in the content information encoder. The low-resolution content encoder shares the last several layers with the high-resolution content encoder to further encourage the additional deconvolutional layers to learn to upsampling content information.
Cross-domain image deblurring
One of the most significant differences between single domain and cross-domain image deblurring is that the blurred image content is much more different from its sharp counterpart during training.Therefore, it’s even more important for us to minimize the semantic distance between the synthetic sharp image and the original blurred image. The perceptual loss term is exactly used to capture this.We hypothesize that the weight for this term should be higher when learning cross-domain image deblurring.
Result
Joint image super-resolution and deblurring result
Our model achieve satisfactory results when jointly super-resolve and deblur text images. Notice that we preserve the ratio of the original, output and target image for better comparison. Even at the presence of significant motion blur, our method can successfully super-resolve and deblur the given low resolution image. Notice that it successfully achieve this while keeping common words, numbers and common mathematical notation likes the equal sign readable.

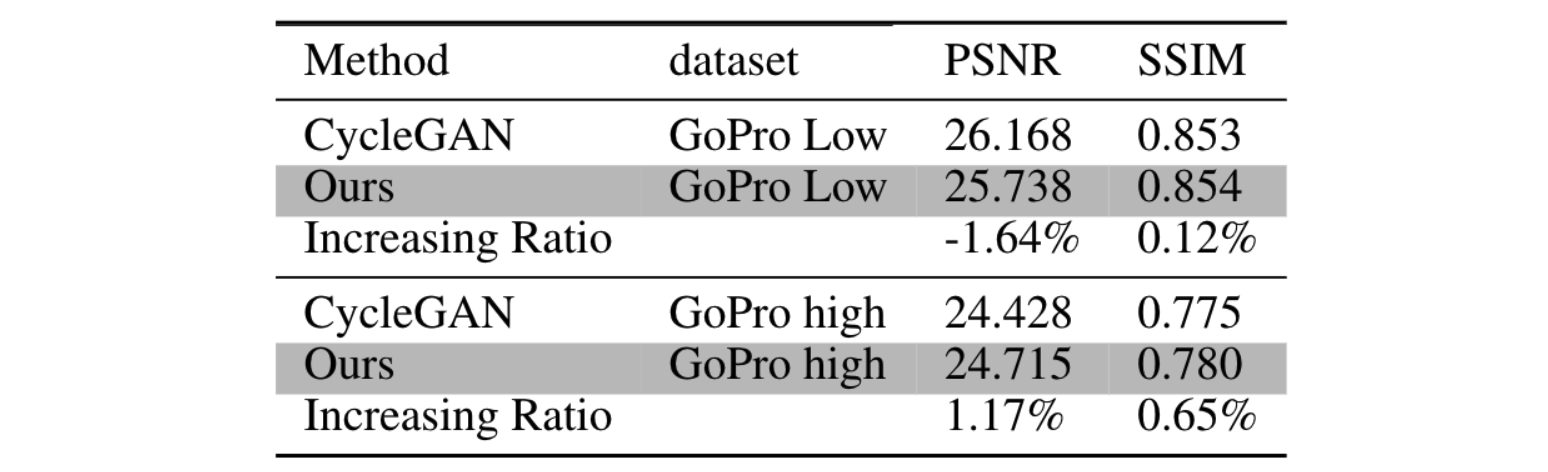
The PSNR and SSIM result of our super-resolve and deblurred output with respect to the ground truth high-resolution, sharp images

More interestingly, our model even learn to color the input image when learning to only super-resolve and deblur it. We conjecture that this is because during unpaired training, some text images with figures are paired with colored images. This example shows that our model can transfer simple image attributes like color and sharpness while preserving semantic details of the original images
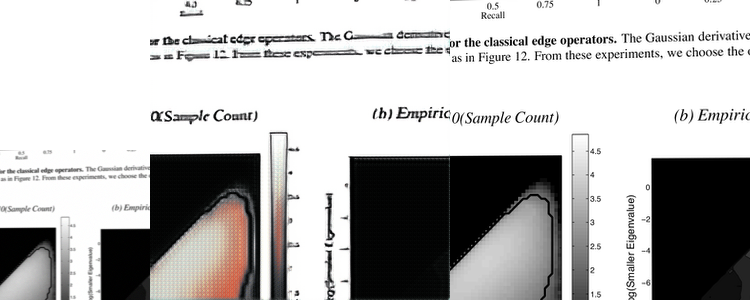
However, our model does suffer from performance drop when deblurring rarely-seen symbols, like foreign characters, webpages or diagrams. It’s worth-noting that at the presence of these symbols, even common words will be deblurred into unrecognizable stripe. We conjecture that the reason might be 1) deblurring Chinese characters/diagrams is intrinsically harder than deblurring English characters; or 2) even though our model learn to disentangle blurring feature information with the content information, it cannot generalize well to unseen/rarely-seen context. In another word, this is more of a limitation on the content encoder module instead of the whole super-resolving deblurring framework. An interesting following up work will be to train our model on deblurring text images containing mainly Chinese characters to see whether our model fails because of the difficulty of the task itself or the encoder’s generalization power.

Cross-domain image deblurring result
We can see that the edges of most objects in the image processed by our method, like the text area of the first image set, the flowers in the third image set,and the car number in the fourth image set are sharper compared to the results of CycleGAN

Our method outperformsCycleGAN in both SSIM and PSNR metrics.
There are still some drawbacks with our method and CycleGAN, We can see that both methods reconstruct human figures very poorly. One possible reason is that there aren’t many human images in the cross-domain dataset for the network to grasp this information.

Despite those drawbacks, the generated images never appear in a different style or shape compared to the original image. In other words, the only difference between the two is their blurriness. It proves that we successfully split the content and blur features in a blurred image using content encoders and blur encoders.
Conclusions & Future Work
We present a CycleGAN-based generative framework that can both learn to jointly super-resolve & deblur images, and to perform cross-domain image deblurring with unpaired training data. Regarding joint image super-resolution and deblurring, our model successfully super-resolve and deblur commonly seen English words, while fail short of deblurring tokens rarely seen in the training set.Regarding cross-domain image deblurring, our model obtains visually satisfactory results with sharper edges of several common objects in the scene, and quantitative results comparable with CycleGAN. Due to our time and computation resource constraint, we have not tried jointly super-resolve & deblur cross domain images. To test whether we truly learn a representation of blurring feature that’s disentangled with image content, it would be interesting to experiment with zero-shot deblurring images of one domain with blurring feature encoder learned from another domain.
References
[1]H.-Y. Lee, H.-Y. Tseng, Q. Mao, J.-B. Huang, Y.-D. Lu, M. Singh, and M.-H. Yang. Drit++:Diverse image-to-image translation via disentangled representations.International Journal ofComputer Vision, pages 1–16, 2020. [2]B. Lu, J.-C. Chen, and R. Chellappa. Unsupervised domain-specific deblurring via disentangledrepresentations. InProceedings of the IEEE Conference on Computer Vision and PatternRecognition, pages 10225–10234, 2019
[3] J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros. Unpaired image-to-image translation usingcycle-consistent adversarial networks. InProceedings of the IEEE international conference oncomputer vision, pages 2223–2232, 2017.
Group Members:
- Qi Huang (EID:qh2466)
Links & Files
- Zhiwen Qiang (EID: zq686)